Large Language Models
1. Introduction to Large Language Models (LLMs)
Historical Context and Evolution of LLMs
The journey of Large Language Models (LLMs) is a testament to the relentless pursuit of knowledge and innovation in the field of artificial intelligence. The genesis of LLMs can be traced back to the early days of machine learning, where rudimentary algorithms were employed to understand and generate human language. These initial models, while groundbreaking for their time, were limited in their capabilities, often producing outputs that were far from human-like.
As computational power increased and datasets grew, the models evolved. The introduction of neural networks, particularly deep learning, marked a significant leap in the capabilities of language models. These models, equipped with multiple layers of interconnected nodes, could process vast amounts of data, learning intricate patterns and relationships within the language.
The transformer architecture, introduced in the seminal paper Attention is All You Need by Vaswani et al., in 2017, revolutionized the field. It brought forth the concept of attention mechanisms, allowing models to focus on specific parts of the input data, akin to how humans pay attention to certain words or phrases when comprehending language. This architecture laid the foundation for the development of LLMs, including the likes of BERT, GPT, and their subsequent iterations.
Significance of LLMs in the Modern AI Landscape
In today’s AI-driven world, LLMs hold a pivotal position. Their ability to understand, generate, and even reason with human language has opened up a plethora of applications. From chatbots providing instant customer support to systems that can draft legal documents, the use cases are vast and varied.
But beyond their practical applications, LLMs represent a significant stride towards the goal of achieving true artificial general intelligence (AGI). These models, with their billions of parameters, come closer than ever before to understanding context, nuance, and the intricacies of human language. They can generate poetry, write essays, and even engage in debates, blurring the lines between machine-generated and human-produced content.
However, with great power comes great responsibility. The rise of LLMs has also sparked discussions about ethics, biases, and the potential misuse of such technology. As we stand on the cusp of what many believe to be a new era in AI, it is imperative to approach the development and deployment of LLMs with caution, ensuring that they are used to benefit humanity as a whole.
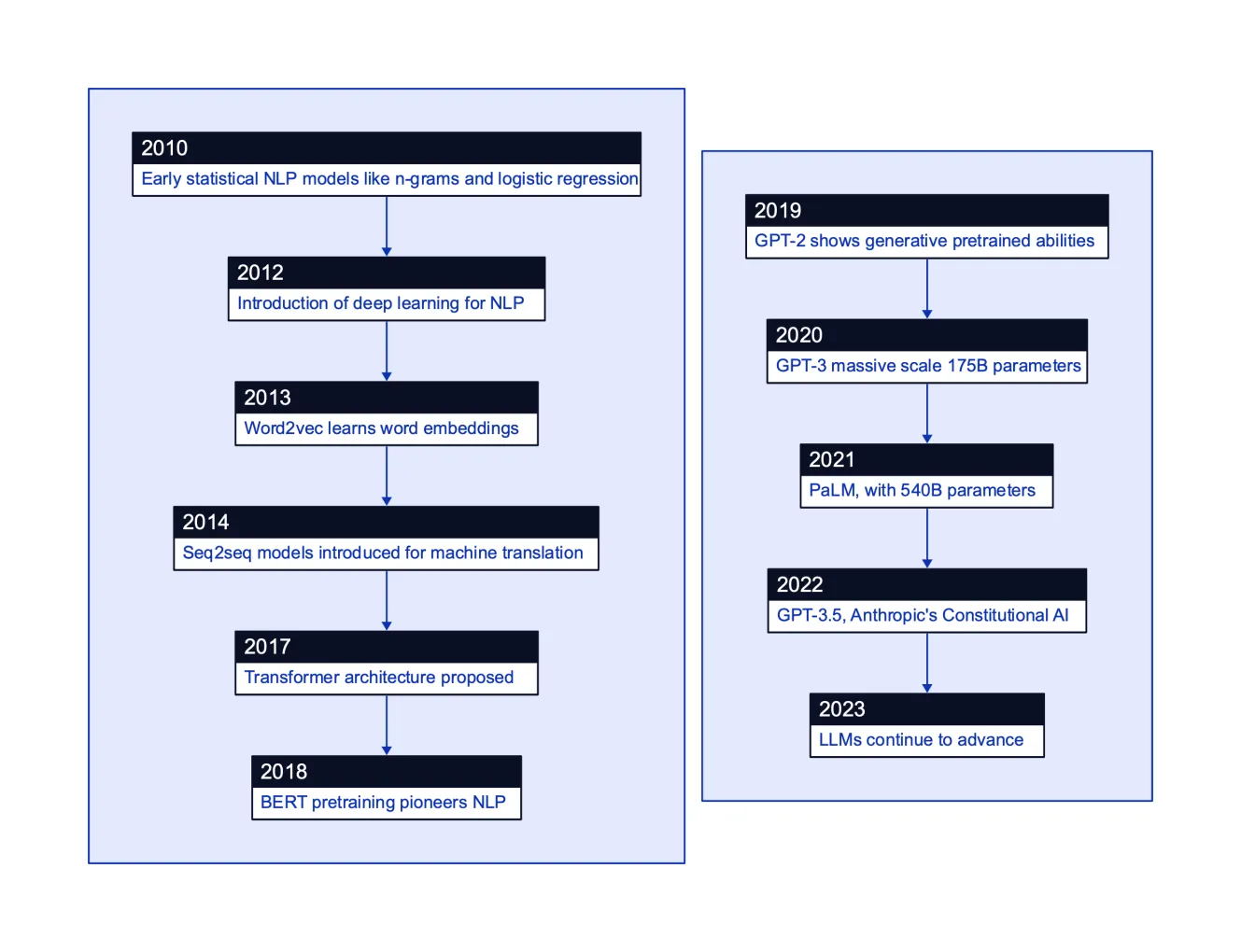
Major innovations in language modeling over the past decade or so, from the rise of deep learning and word embeddings, to transformer networks enabling models like BERT and GPT-3, up to the latest LLMs with hundreds of billions of parameters
2. The Science Behind LLMs
Basic Principles: Neural Networks, Deep Learning, and Transformers
At the heart of Large Language Models (LLMs) lies a complex interplay of mathematical functions, algorithms, and data structures. To truly grasp the prowess of LLMs, one must first understand the foundational principles that drive them.
Neural Networks: Inspired by the human brain’s neural structure, artificial neural networks consist of interconnected nodes or “neurons”. These networks are designed to recognize patterns by processing input data and adjusting their internal weights. Each neuron receives input, processes it (often with a non-linear function), and sends the output to the next layer.
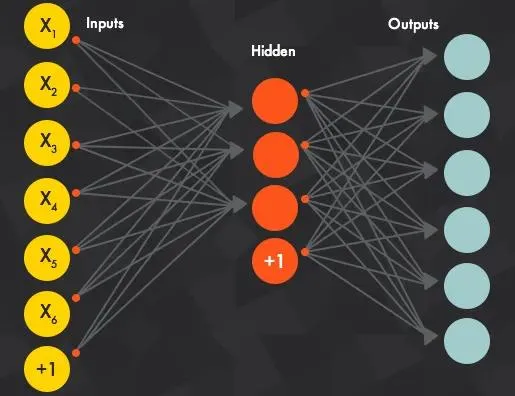
An illustration of a sample neural network
Deep Learning: A subset of machine learning, deep learning employs neural networks with three or more layers. These deep networks can model complex, non-linear relationships. The “depth” of these models allows them to learn through vast amounts of unstructured data, making them particularly suited for tasks like image and speech recognition, and, of course, natural language processing.
Transformers: A game-changer in the realm of LLMs. Traditional neural networks process data sequentially, but transformers revolutionized this by introducing the ability to process input data in parallel. The key component, the “attention mechanism”, allows the model to focus on different parts of the input text, much like how humans pay selective attention. This parallel processing capability makes transformers highly efficient and capable of handling long sequences of data, a prerequisite for understanding context in language.
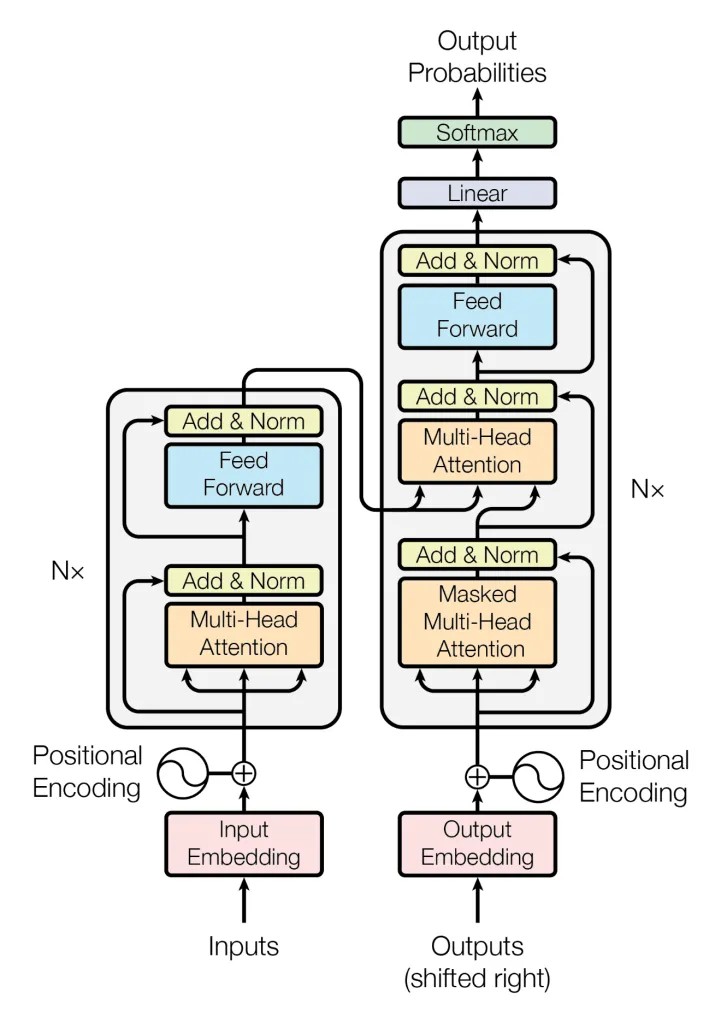
The transformer neural network envisioned
The Architecture of LLMs: Layers, Attention Mechanisms, and Embeddings
Delving deeper into the architecture, LLMs are a marvel of design and functionality.
Layers: LLMs consist of multiple layers, each containing a multitude of neurons. As data passes through these layers, it undergoes a series of transformations, with each layer extracting and processing different features. For instance, in the context of language, initial layers might recognize letters, intermediate layers may identify words or phrases, and deeper layers could understand sentence structures or even entire paragraphs.
Attention Mechanisms: One of the standout features of the transformer architecture. Instead of processing data sequentially, attention mechanisms allow the model to focus on specific parts of the input simultaneously. This “attention” can be visualized as weights, with higher weights indicating parts of the input that the model deems more important for a given task.
Embeddings: At the start of the processing pipeline, words or tokens are converted into vectors using embeddings. These vectors capture the semantic meaning of words, placing similar words closer in the vector space. Pre-trained embeddings, like Word2Vec or GloVe, have been instrumental in improving the efficiency of LLMs, as they provide a starting point for the model to understand language.
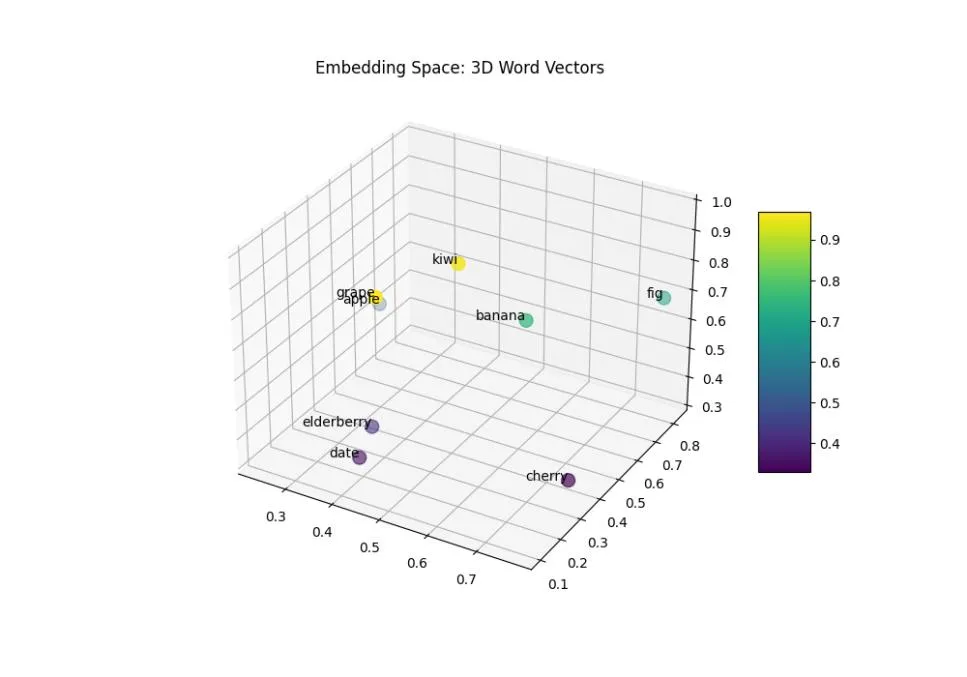 A 3-D graph showing word embeddings
A 3-D graph showing word embeddings
By understanding the underlying science and architecture of LLMs, one gains a profound appreciation for their capabilities.
3. Training Large Language Models: A Deep Dive
The Importance of Data: Quantity, Quality, and Diversity
The adage “garbage in, garbage out” holds particularly true for LLMs. The quality of the training data directly influences the model’s performance. But it’s not just about quantity; the diversity and representativeness of the data are equally crucial.
Quantity: LLMs, with their billions of parameters, require vast amounts of data to train effectively. This voluminous data helps the model discern intricate patterns and relationships within the language.
Quality: Raw data often contains noise, inconsistencies, and inaccuracies. Preprocessing and cleaning the data are essential steps to ensure that the model learns from accurate and relevant information.
Diversity: To be truly effective, LLMs must understand the nuances, dialects, and variations of a language. Training data should encompass a wide range of sources, styles, and contexts to ensure comprehensive language understanding.
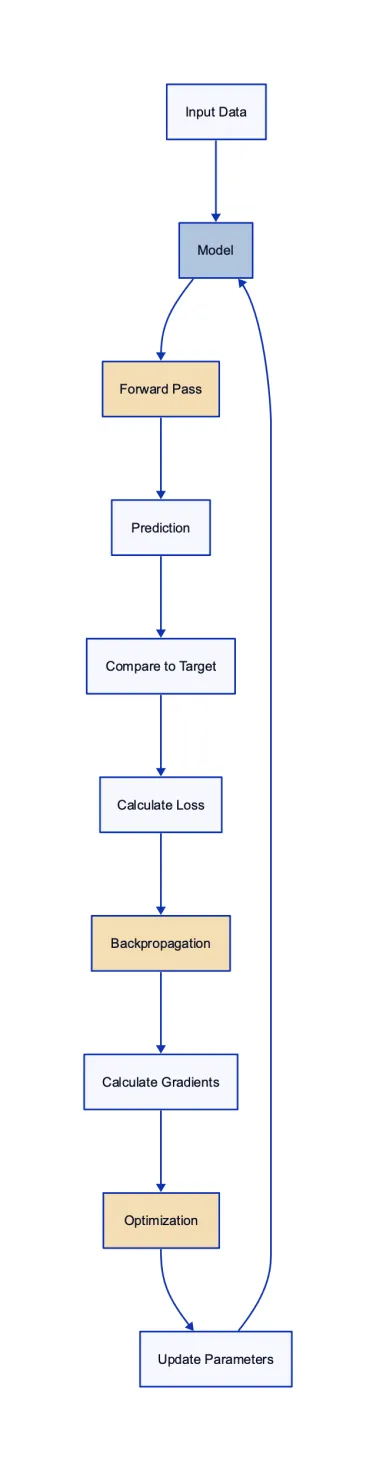
The Training Process: Forward Pass, Backpropagation, and Optimization
Training an LLM is an iterative process, where the model continuously adjusts its internal parameters to reduce the difference between its predictions and the actual outcomes.
Forward Pass: The model processes the input data, layer by layer, to produce an output. This output is then compared to the actual target to calculate the loss, a measure of how far off the model’s predictions are from the desired outcome.
Backpropagation: This is where the magic happens. The model calculates the gradient of the loss with respect to each parameter. In simpler terms, it determines how each parameter influenced the final error.
Optimization: Using optimization algorithms, like Adam or SGD, the model adjusts its parameters in the direction that reduces the loss. Over multiple iterations, this process helps the model converge to a state where its predictions are as close as possible to the actual targets.
Fine-tuning: Tailoring LLMs for Specific Tasks
While pre-trained LLMs are impressive, they often need to be fine-tuned to excel at specific tasks. Fine-tuning involves training the model on a smaller, task-specific dataset, allowing it to adapt its general language understanding to the nuances of the particular task.
For instance, an LLM trained on vast amounts of general text data can be fine-tuned on medical literature to assist in medical diagnosis or on legal documents to aid in legal research.
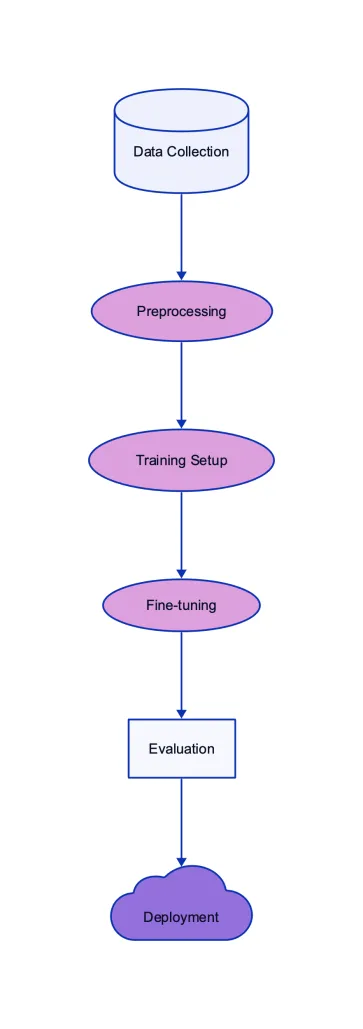
Consider the task of training the LLAMA 2 model to generate news articles. The initial pre-trained model has a broad understanding of language but might lack the stylistic and structural nuances of journalistic writing.
Data Collection: Gather a diverse set of news articles, spanning various topics, styles, and sources.
Preprocessing: Clean the data, remove duplicates, and segment articles into meaningful chunks or sequences.
Training Setup: Initialize the LLAMA 2 model with pre-trained weights. Define the loss function (e.g., cross-entropy loss for text generation) and the optimizer.
Fine-tuning: Feed the model sequences from the news articles. After each forward pass, calculate the loss and adjust the model parameters using backpropagation.
Evaluation: Periodically evaluate the model’s performance on a separate validation set. Monitor metrics like perplexity to gauge the model’s language generation capabilities.
Deployment: Once satisfied with the model’s performance, deploy it for generating news articles. Continuously monitor and retrain as needed to adapt to evolving language trends.
Fine-Tuning Process
One of the powers of large language models (LLMs) like GPT-3 is that they can be adapted or “fine-tuned” to better suit specific tasks. This allows them to move beyond general language proficiency to mastery of niche domains.
Let’s compare a generic, pre-trained LLM to one that has been fine-tuned:
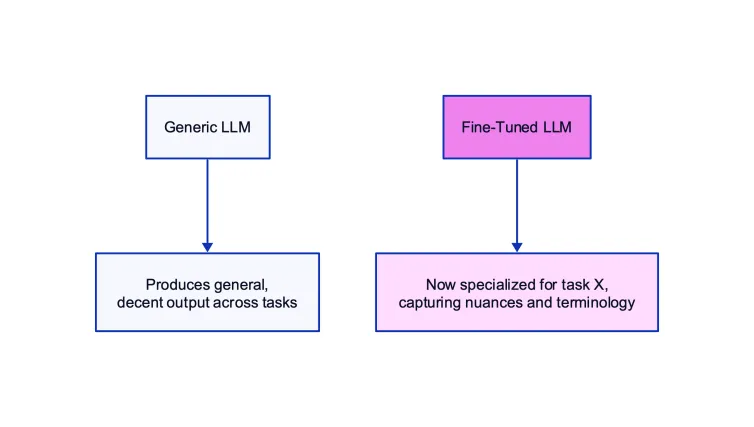
On the left is a general LLM with broad capabilities. On the right, we see the same architecture fine-tuned on data from task X. It has adapted its parameters to specialize, producing outputs that are tuned for the nuances and vocabulary of that niche.
This ability to specialize makes LLMs far more versatile and useful. The same model can morph into a product review generator, an SQL query writer, or a patent search engine through proper fine-tuning.
Training LLMs is a meticulous process, requiring a harmonious blend of data science, computational prowess, and domain expertise. As these models continue to evolve, their training methodologies will undoubtedly become more refined, paving the way for even more advanced and nuanced language understanding.
4. Challenges and Considerations in LLM Training
Computational Demands: The Need for Power
Training LLMs, especially those with billions of parameters, is computationally intensive. The sheer size of these models, combined with the vast amounts of data they process, places significant demands on hardware.
GPUs and TPUs: These specialized hardware components accelerate matrix operations, a fundamental aspect of deep learning. Training LLMs without them would be impractically slow. Modern LLMs often require clusters of these units, working in tandem, to achieve reasonable training times.
Memory Constraints: LLMs, given their size, can easily exceed the memory capacities of individual GPUs or TPUs. Techniques like model parallelism, where different parts of the model are placed on different devices, become essential.
Energy Consumption: The environmental impact of training LLMs is a growing concern. The energy required for training can be substantial, leading to significant carbon footprints. Researchers and organizations are actively seeking more energy-efficient training methods.
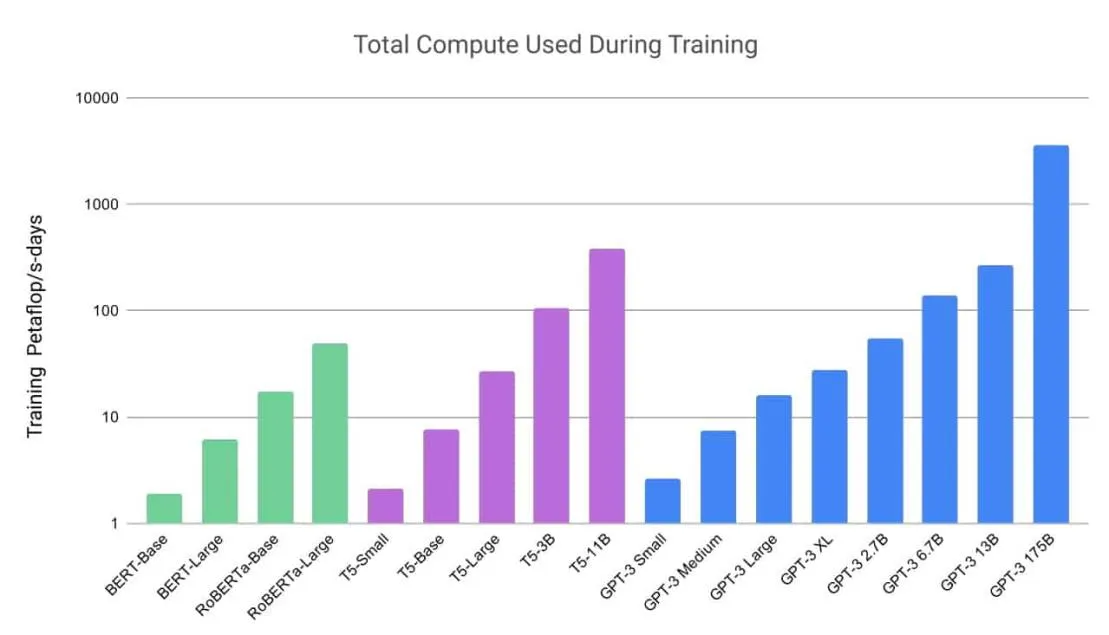
An illustration of the computing demands for training LLM’s
Data Biases: The Pitfalls of Imperfect Data
Every dataset carries biases, and when LLMs are trained on biased data, they inherit and often amplify these biases. This can lead to models that produce skewed, unfair, or even harmful outputs.
Source Biases: If training data predominantly comes from specific sources or regions, the model might develop a narrow or regional perspective. For instance, an LLM trained mostly on Western literature might struggle with or misinterpret Eastern contexts.
Historical Biases: Old texts and documents often carry the prejudices and misconceptions of their times. LLMs trained on such data might inadvertently perpetuate outdated or harmful views.
Addressing Biases: Active efforts are required to identify and mitigate biases in training data. Techniques like data augmentation, where synthetic data is generated to balance out underrepresented classes, can be beneficial.
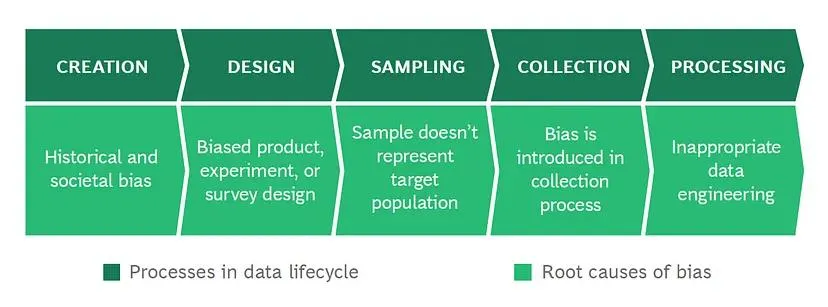
Types of data bias
Hyperparameter Tuning: Finding the Right Balance
Hyperparameters, parameters not learned from the data, play a crucial role in LLM training. They influence aspects like learning rate, batch size, and model architecture.
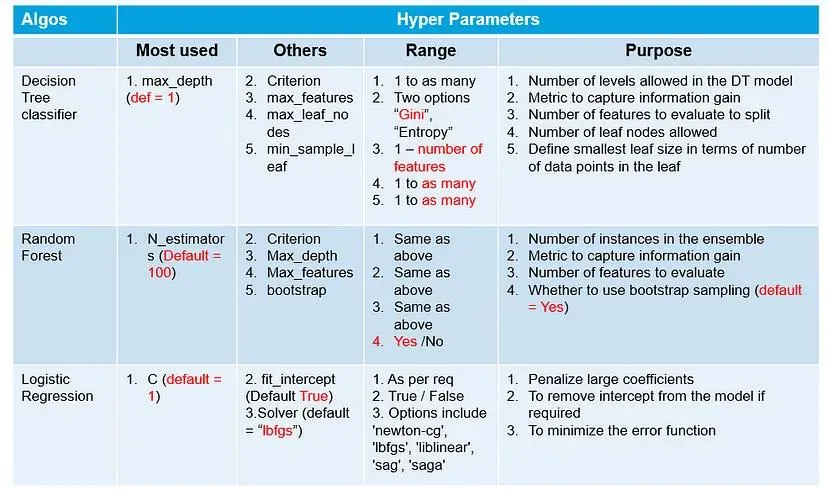
Examples of Hyperparameters in common machine learning models.
Grid Search vs. Random Search: While grid search systematically explores combinations of hyperparameters, random search samples them randomly. Both methods have their merits and can be used to find optimal hyperparameter settings.
Automated Hyperparameter Optimization: Tools like Bayesian optimization can automatically find the best hyperparameters, reducing the need for manual experimentation.
Regularization and Overfitting: Walking the Tightrope
Overfitting occurs when the model becomes too attuned to the training data, losing its ability to generalize to new, unseen data. Regularization techniques add constraints to the learning process to prevent overfitting.
Dropout: A popular regularization technique where random neurons are “dropped out” or deactivated during training. This prevents the model from becoming overly reliant on any specific neuron.
Early Stopping: Monitoring the model’s performance on a validation set and halting training when performance plateaus or starts deteriorating can prevent overfitting.
5. The Fine-tuning Process
Data Collation: The Foundation of Fine-tuning
Before diving into the fine-tuning process, it’s crucial to have the right data. This step involves not just gathering data, but ensuring it’s relevant and well-prepared for the task at hand.
Gathering Data: Depending on the task, this could involve collecting new data, using existing datasets, or a combination of both. For instance, if the goal is to fine-tune an LLM for medical diagnosis, datasets with medical case studies might be sought.
Preprocessing: Raw data is rarely ready for immediate use. It might need cleaning, normalization, or transformation. This step ensures the data is in a format the model can understand and learn from effectively.
Configuration: Setting the Stage for Success
Before training begins, the environment must be set up correctly. This involves configuring various parameters that influence the training process.
Hyperparameters: These are parameters that aren’t learned from the data but are set beforehand. They include aspects like the learning rate (how quickly the model adjusts based on errors) and batch size (how many data points are processed at once).
Model Architecture: While the base architecture remains the same, certain layers might be frozen during fine-tuning to preserve knowledge, while others are adjusted to better suit the new task.
Training: The Heart of Fine-tuning
With data and configurations ready, the actual fine-tuning begins. This is an iterative process where the model learns from the data, adjusting its parameters to reduce errors.
Iterative Process: The model processes the data in batches, making predictions and adjusting based on the errors it makes. This process is repeated multiple times (epochs) until the model’s performance plateaus or starts to degrade.
Challenges: Fine-tuning isn’t without challenges. There’s a risk of overfitting, where the model becomes too specialized in the training data and loses its ability to generalize. Regularization techniques, like dropout, can help mitigate this.
Evaluation: Measuring and Refining
After training, it’s essential to evaluate the model’s performance to ensure it meets the desired standards.
Metrics: Depending on the task, different metrics might be used. For classification tasks, accuracy, precision, recall, and F1 score are common. For regression tasks, mean squared error or mean absolute error might be used.
Benchmarks: Comparing the fine-tuned model’s performance against established benchmarks or baseline models gives a sense of its relative prowess.
Continuous Improvement: Fine-tuning is rarely a one-off process. As more data becomes available or as the task evolves, the model might be re-evaluated and fine-tuned further to maintain or improve its performance.
6. QLora: A Paradigm Shift in Fine-tuning
Introduction to the QLora Platform
In the vast realm of Large Language Models, QLora emerges as a beacon for those looking to fine-tune their models with precision and efficiency. It’s not just another platform; it’s a paradigm shift in how we approach the fine-tuning of LLMs.
QLora, with its intuitive interface and robust back end, offers a seamless experience for both novice and expert AI practitioners. It simplifies the complexities of fine-tuning, making it more accessible to a broader audience.
Features, Benefits, and How It Stands Out
Features:
GPU Support: QLora leverages the power of GPUs, ensuring faster training times and efficient model optimization.
Customizable Workflows: Tailor your fine-tuning process to your specific needs, from data preprocessing to model evaluation.
Collaborative Environment: Work in teams, share your progress, and get feedback, all within the platform.
Benefits:
Reduced Training Time: With optimized algorithms and GPU support, reduce your model’s time-to-market.
Enhanced Accuracy: Achieve better results with QLora’s advanced fine-tuning techniques.
Cost-Efficient: Save on computational costs with QLora’s efficient resource management.
How It Stands Out: QLora isn’t just about features; it’s about the experience. It bridges the gap between complex AI processes and user-friendly interfaces. Its community-driven approach, coupled with cutting-edge technology, makes it a preferred choice for many AI professionals.
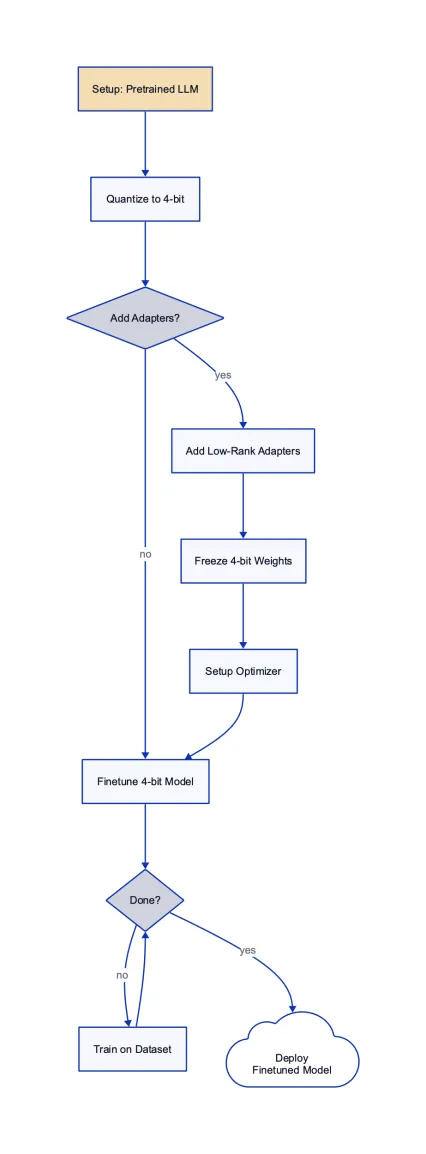
Step-by-Step Guide to Fine-tuning Using QLora
-
Setup: Begin by setting up your QLora account and configuring your workspace. Ensure you have the necessary data and resources in place.
-
Data Preparation: Upload your dataset, preprocess it, and split it into training, validation, and test sets using QLora’s tools.
-
Model Selection: Choose the base LLM you wish to fine-tune. QLora supports a range of popular models, including LLAMA 2.
-
Fine-tuning Configuration: Set your hyperparameters, choose your optimizer, and configure the training parameters.
-
Training: Initiate the fine-tuning process. Monitor progress with real-time visualizations and logs.
-
Evaluation: Once training is complete, evaluate your model’s performance using QLora’s suite of metrics and visualization tools.
-
Deployment: Deploy your fine-tuned model to your desired environment, be it cloud, on-premises, or edge devices.
7. Challenges in Training LLMs
Computational Demands and Solutions
The training of Large Language Models (LLMs) is a computationally intensive task. With models boasting billions, or even trillions, of parameters, the computational requirements can be staggering. Training these models demands high-performance GPUs or TPUs, vast memory, and efficient data pipelines.
Solution: Distributed training and model parallelism have emerged as viable solutions. By splitting the model across multiple devices or even clusters, training can be accelerated. Cloud platforms also offer scalable solutions, allowing researchers to rent computational resources as needed.
Addressing Biases and Ensuring Data Diversity
LLMs are only as good as the data they’re trained on. Biases in training data can lead to biased model outputs. These biases can range from racial and gender biases to more subtle biases related to a particular domain or culture.
Solution: Curated datasets that represent diverse perspectives and rigorous auditing processes can help. Techniques like data augmentation and synthetic data generation can also be employed to enhance diversity. Active research in the field of AI ethics is paving the way for more robust solutions to address biases.
Overfitting, Underfitting, and Model Generalization
Overfitting: When a model performs exceptionally well on training data but poorly on unseen data.
Underfitting: When a model fails to capture the underlying patterns in the data, resulting in poor performance on both training and test data.
Model Generalization: The ability of a model to perform well on new, unseen data.
Solution: Regularization techniques, dropout layers, and early stopping are common strategies to combat overfitting. Ensuring a diverse training dataset and using techniques like cross-validation can enhance model generalization.
8. Closing Thoughts
The world of artificial intelligence has witnessed a paradigm shift with the introduction and evolution of Large Language Models (LLMs). Their transformative potential is evident in the myriad of applications they power, from chatbots to content generators, and from research tools to creative assistants. As we reflect on the journey of LLMs and their impact, a few key themes emerge.
The Transformative Potential of LLMs
LLMs have redefined the boundaries of what machines can achieve in terms of understanding and generating human-like text. Their ability to process vast amounts of information, learn from it, and produce coherent and contextually relevant outputs has paved the way for innovations across industries. Whether it’s in healthcare, where LLMs assist in diagnosing conditions based on patient narratives, or in entertainment, where they aid in scriptwriting or game design, the transformative potential of these models is undeniable.
Encouraging Responsible and Ethical AI Development
With great power comes great responsibility. The capabilities of LLMs, while impressive, also bring forth ethical dilemmas. The potential for misuse, whether in spreading disinformation or in perpetuating biases, is a concern that the AI community must address. It’s imperative that as we advance in our understanding and utilization of LLMs, we also instill a sense of responsibility in their development and deployment. Ethical considerations, transparency in model training, and a commitment to fairness should be at the core of all LLM-related endeavors.
The Exciting Journey Ahead for AI Enthusiasts and Professionals
For those at the forefront of AI research, development, and application, the journey with LLMs is filled with promise. The continuous evolution of these models, coupled with advancements in related AI technologies, signifies a future where the integration of LLMs in our daily lives becomes seamless. The road ahead is paved with opportunities for further research, interdisciplinary collaboration, and the creation of solutions that address global challenges.
As we stand at this juncture, looking back at the strides made and looking forward to the possibilities, one thing is clear: the world of AI, powered by LLMs, holds a promise of innovation, growth, and positive transformation.