QLora Technical Report
In the cutting-edge domain of artificial intelligence, the role of large language models (LLMs) like GPT-4 has been monumental. These models, characterized by their vast number of parameters, have fundamentally transformed capabilities in natural language understanding and generation. However, the very feature that makes them powerful – their enormous size – also presents significant challenges. Traditional methods of fine-tuning these behemoths are not only computationally intensive but also demand considerable energy resources, posing a significant barrier to their widespread adoption and application.
This is where LoRA (Low-Rank Adaptation) and its advanced variant, QLoRA (Quantized Low-Rank Adaptation), emerge as groundbreaking solutions. LoRA’s core innovation lies in its approach to fine-tuning, where it introduces trainable low-rank matrices into the transformer layers of LLMs. This methodology enables subtle yet effective adjustments to the model’s behavior, optimizing its performance for specific tasks without the need for extensive retraining. By focusing on these strategic modifications, LoRA ensures that the fine-tuning process remains efficient, both in terms of computational resources and time.
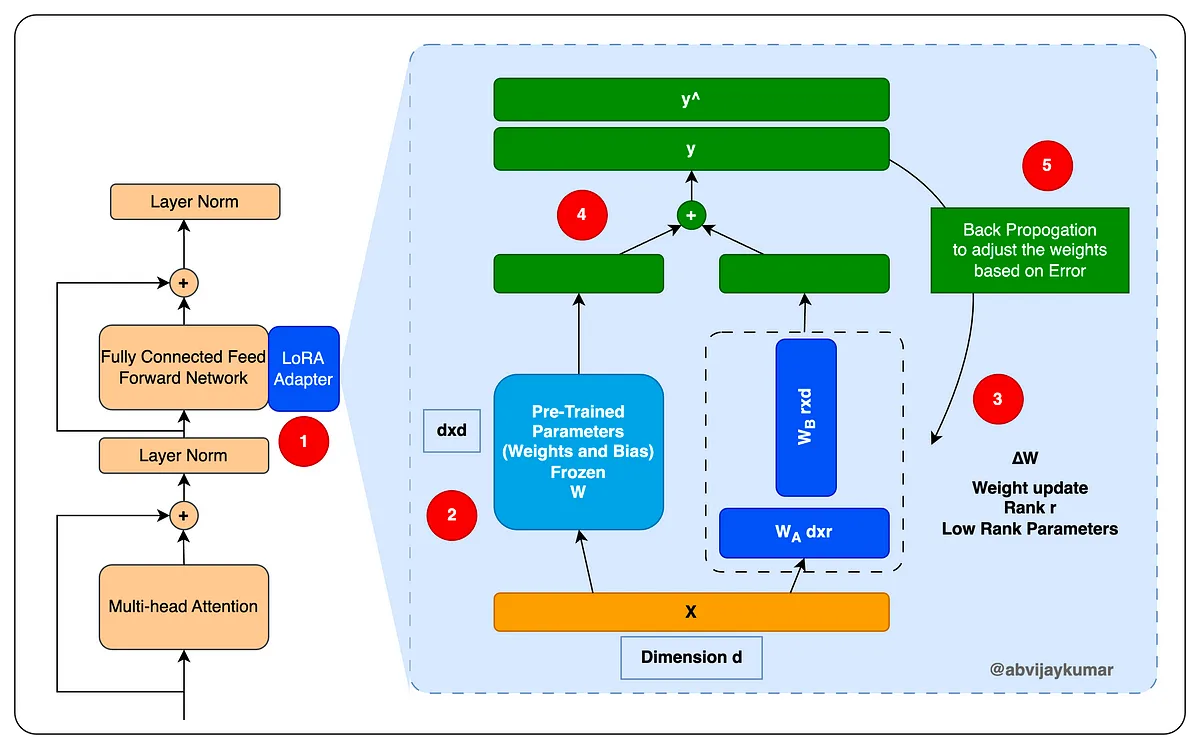
A neural network utilizing a LoRA Adapter to update pre-trained network parameters efficiently [Source: @abvijaykumar]
QLoRA takes this a step further by integrating the concept of quantization into LoRA’s framework. Quantization effectively reduces the numerical precision of the model’s data, leading to a substantial decrease in memory usage and computational load. This enhancement makes it feasible to fine-tune large models on hardware that would otherwise be inadequate for such tasks, significantly lowering the barrier to entry for utilizing state-of-the-art LLMs.
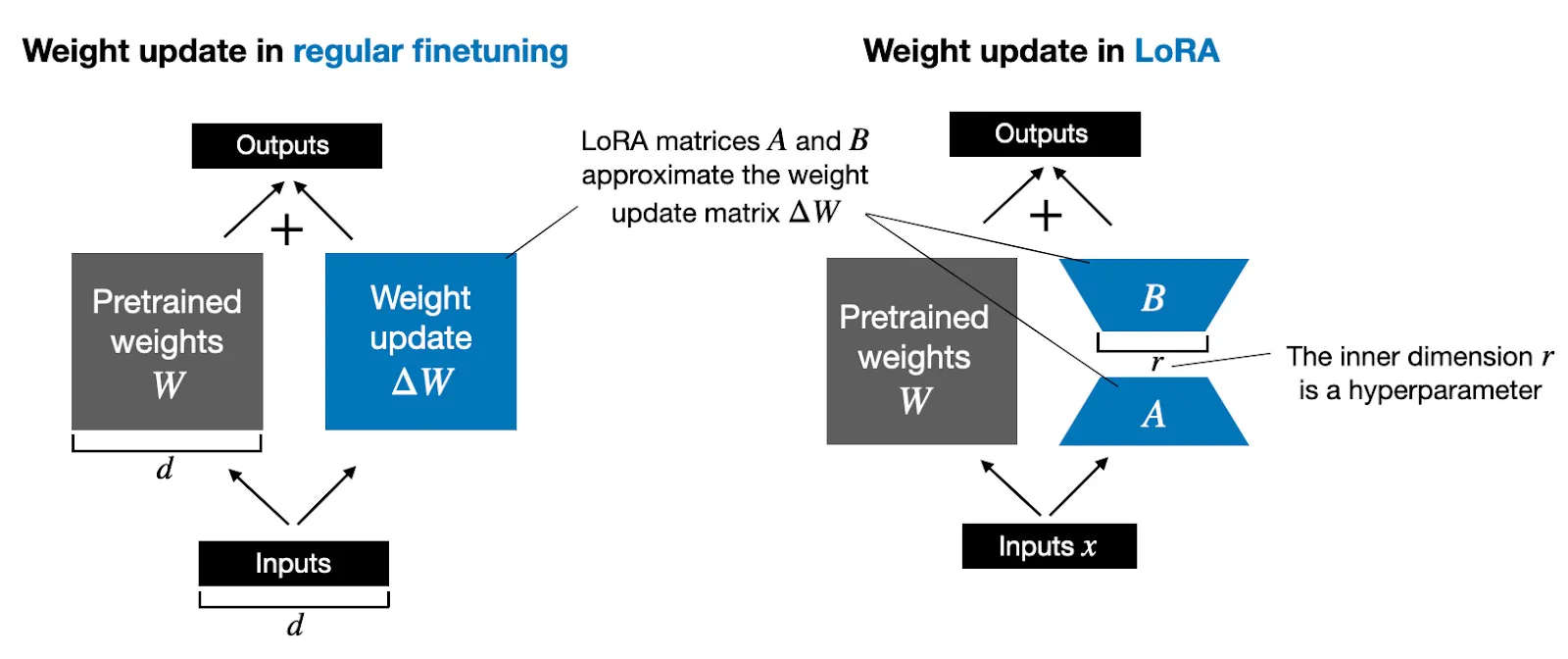
Comparative Overview of Weight Update Mechanisms: Traditional Finetuning vs. Low-Rank Adaptation (LoRA)
The brilliance of LoRA and QLoRA lies not just in their technical ingenuity but also in their practical implications. By mitigating the computational and energy demands of fine-tuning LLMs, these methods democratize access to advanced AI technologies. They enable a broader range of researchers, developers, and businesses to harness the power of LLMs, paving the way for innovative applications that were previously unfeasible due to resource limitations.
Through LoRA and QLoRA, the landscape of AI is witnessing a paradigm shift, where the power of large language models becomes more accessible and sustainable. This evolution marks a critical step in the journey towards a more inclusive and efficient use of AI technologies in various sectors, from healthcare and finance to education and entertainment.
These algorithms were developed to tackle significant challenges in the fine-tuning of large language models (LLMs) like GPT-4. The primary problems they address include:
- Computational Efficiency
- Traditional fine-tuning methods for LLMs require substantial computational resources, often needing powerful and expensive hardware. This limits the accessibility and feasibility of fine-tuning LLMs for many researchers and developers.
- Memory Constraints
- The size of these models often exceeds the memory capacity of standard GPUs. This presents a barrier for fine-tuning and utilizing these models, particularly in resource-constrained environments.
- Energy Consumption
- The energy requirements for training and fine-tuning large-scale models are significant, raising concerns about the environmental impact and sustainability of using such models.
LoRA introduces a method to efficiently update model parameters without the need to retrain the entire model. By inserting low-rank matrices into specific layers, it offers a more resource-efficient way of fine-tuning. QLoRA builds upon this by adding quantization, reducing the precision of numerical data in the model, thereby further decreasing the memory and computational requirements. This allows for fine-tuning larger models on less powerful hardware, making the use of advanced LLMs more sustainable and accessible.
A primer on model efficiency
To tackle the challenges in training LLMs, researchers have turned to LoRA. Originally proposed in 2021 by researchers at Google Brain and Stanford, LoRA provides a thrifty approach to finetune LLMs. The method inserts tiny “adapter” modules into a frozen, pretrained LLM. During finetuning, gradients are only propagated through these adapters, keeping the original parameters constant.
Formally, consider a standard linear transformation in a transformer layer:
LoRA would modify this to:
Where
is a low-rank matrix, factorised as
This simple change provides a limited set of parameters to update, massively reducing computational costs.
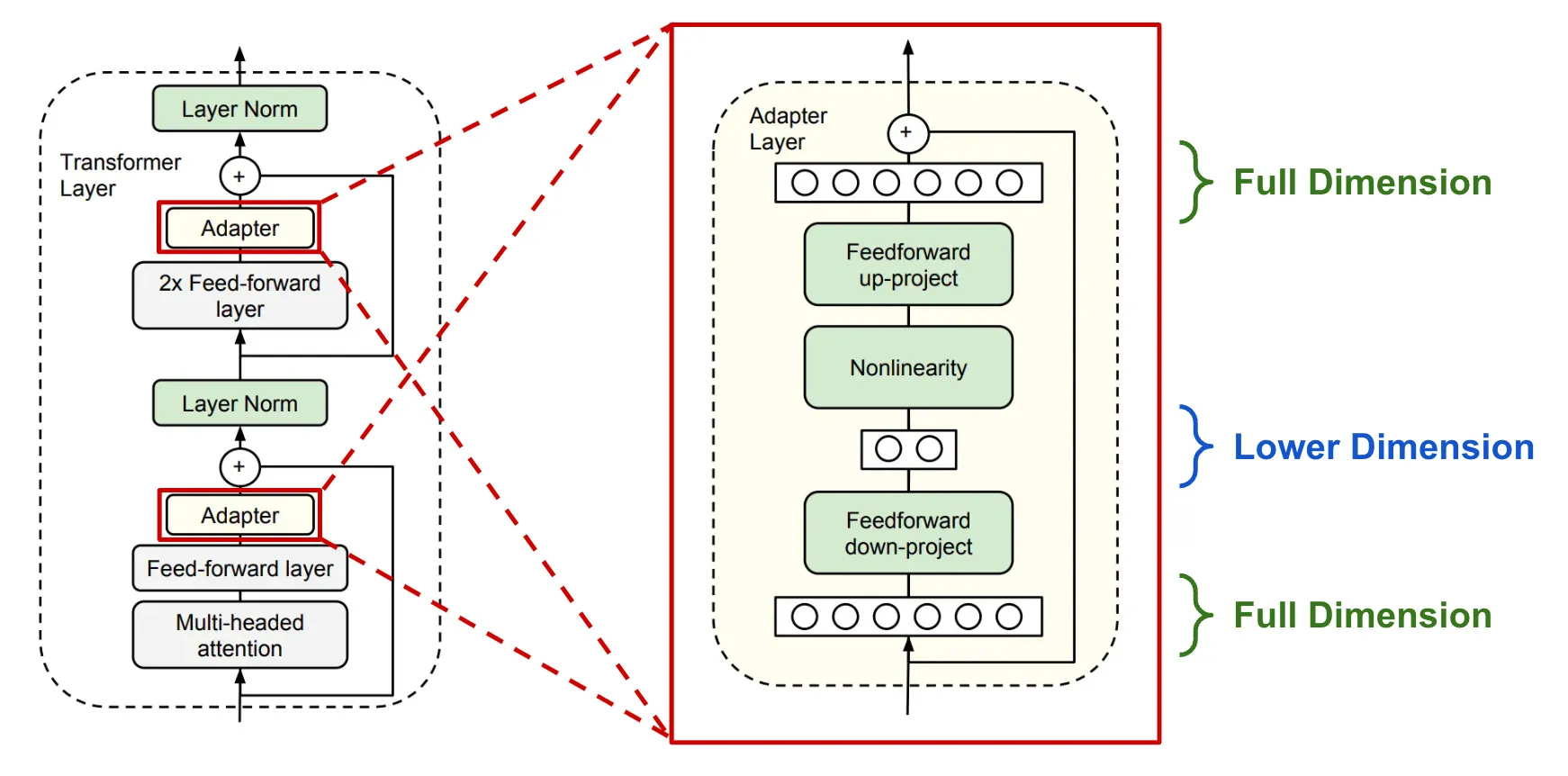
Diagram of a Transformer Model with Adapter Layers for Dimensionality Manipulation
Though LoRA adapters are small, numerous adapters throughout a pretrained LLM accumulate to sufficient capacity for finetuning. Critically, hundreds of LoRA adapters consume orders of magnitude less memory than the model’s original parameters. This lean-and-mean approach slashes hardware requirements, bringing LLMs within reach of mere mortals.
Pushing the limits with model compression
LoRA makes LLM finetuning frugal, but Quantized LoRA (QLoRA) makes it downright stingy. QLoRA combines LoRA with quantization, a technique that shrinks models by reducing the precision of parameters. For instance, switching a model’s 32-bit floats to 4-bit quantized values immediately condenses it 8-fold. Integrating quantization lets QLoRA yield striking compute savings, enabling fine-tuning of multibillion parameter LLMs on modest hardware.
QLoRA typically quantizes the pretrained model to 4 bits before appending adapters. While quantization can hamper representational capacity, QLoRA shows that low-rank adapters can recover this loss. The result is a svelte quantized LLM with adapters that retains the original model’s performance. QLoRA also employs tricks like quantizing the quantization parameters themselves (“double quantization”) to further trim memory waste.
The optimal balance between model size, precision and hardware constraints depends on the application. But QLoRA’s sharpened Swiss Army knife of efficiency techniques advances the leading edge. For AI researchers, QLoRA brings a supercomputing-scale LLM within reach of their laptops and budgets.
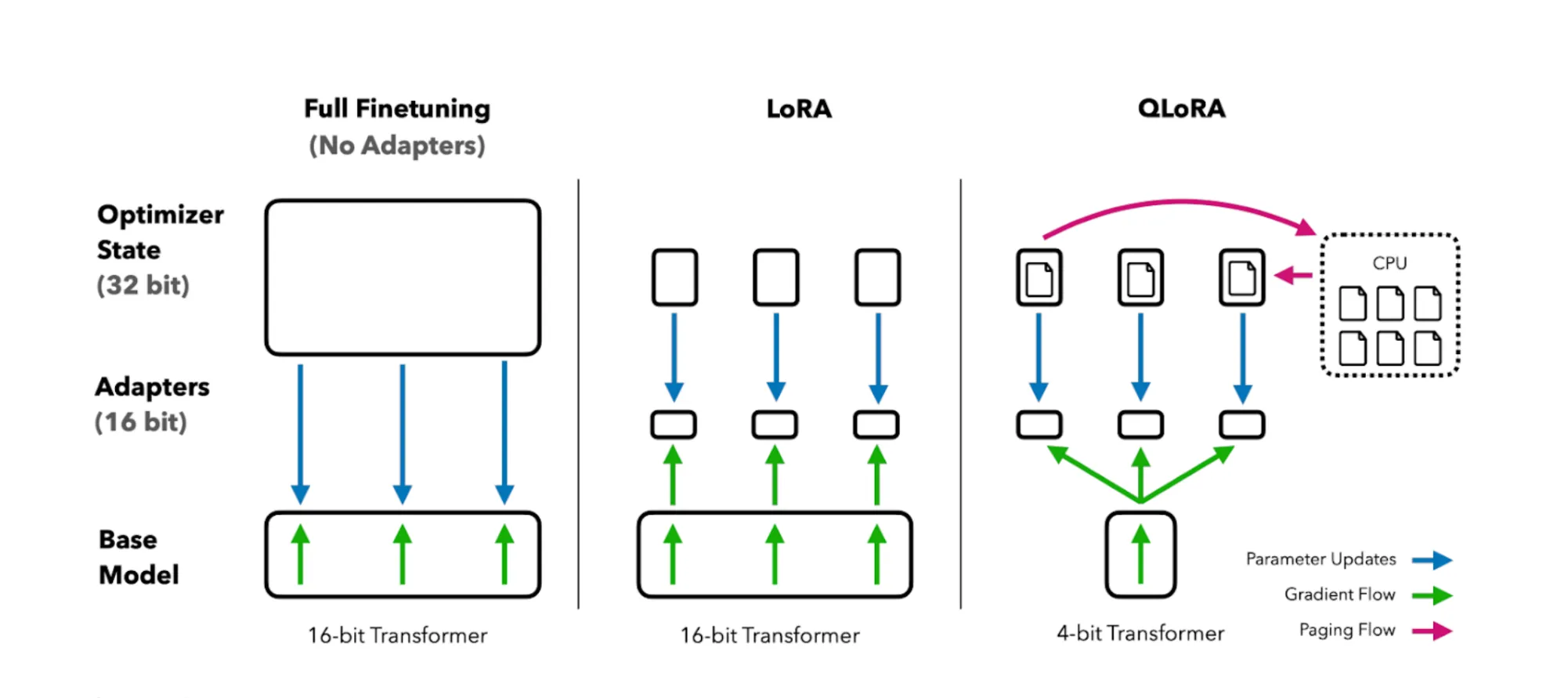
Comparative Schematic of Full Finetuning, LoRA, and QLoRA Techniques in Transformer Models with Bit Precision and Computational Flow Indicators
Pushing model efficiency to the edge
The motivation for quantization is straightforward: less precision means less memory. Halving the number of bits cuts the memory footprint in half. For example, switching a model’s 32-bit floating point values to 4-bit reduces the size ~8x. This compresses models to fit more easily within hardware constraints.

32-bit floats have a larger memory footprint compared to 4-bit integers, yielding an 8x memory reduction
The basic quantization operation is:
Where x is the original full-precision value (e.g. 32-bit float) and scale is a scaling factor that reshapes the distribution of x to match the range representable by the low-precision format (e.g. 4-bit int). Applying Q(x) quantizes each value by rounding to the nearest discrete level available in the reduced bit range.
Simply quantizing all of a model’s parameters together with a single scale leads to poor results. The optimal scale differs across layers, due to variation in parameter statistics. QLoRA addresses this via block-wise quantization, partitioning parameters into smaller blocks that are quantized independently, each with their own scale.
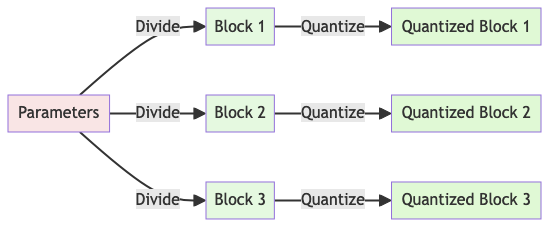
Block-wise quantization divides up parameters into separate blocks before quantizing
The block size presents a tradeoff. Smaller blocks allow finer-grained scale values that maximize utilization of the low-precision range. But more blocks require more scale values to be stored, increasing overhead.
QLoRA tunes block size to balance this tradeoff.
In block-wise quantization, the model parameters are partitioned into blocks that are quantized independently with their own scaling factors. The block size presents a tradeoff between quantization granularity and overhead:
- Smaller block sizes allow more fine-grained quantization as each block gets its own optimized scaling factor based on its value distribution. This maximizes utilization of the low-precision bit range.
- However, more blocks require more scaling factors to be stored. These scale values constitute overhead that increases memory usage.
QLoRA tunes the block size to balance this tradeoff. Some considerations:
- Larger layers tend to use larger block sizes. For example, block size of 1024 or higher for large transformer layers with millions of parameters. Smaller layers use smaller blocks.
- Block size is proportionate to the hardware memory constraints. More restricted memory requires smaller blocks to minimize scale value overhead.
Layers with very skewed and non-normal parameter distributions may need smaller blocks to accommodate variability. Typical block sizes range from 32 to 1024 parameters per block, but can be larger or smaller as needed. The optimal block size depends on the model architecture, layer dimensions, parameter statistics, memory constraints, and accuracy targets.
QLoRA quantizes different layers with different block sizes tailored to each layer’s characteristics. Block size can be automatically tuned by running quantization trials with different configurations and measuring the accuracy.
The key tradeoff is that smaller block sizes allow more precise quantization, but incur more overhead from storing additional scale values. QLoRA balances this tradeoff in a few ways:
- Sets a memory budget for the total overhead. For example, allowing the scale values to consume up to 5% more memory than the quantized parameters.
- Tunes block size so the layer’s parameters and scale values fit within the hardware memory constraints. Larger layers get larger blocks.
- Uses profiling and analysis to determine the sensitivity of each layer to quantization error. Layers that are more sensitive get smaller blocks for higher precision.
- Employs mixed block sizes tailored to each layer, rather than fixed global block size. This provides precision where needed.
- Leverages model structure. Blocks typically do not span across non-contiguous chunks of memory, like attention heads.
- Reduces block count impact via schemes like shared scales, where one factor is shared across blocks.
- Double quantization of scale values reduces their overhead.
- Assesses accuracy tradeoffs via quantization trials with different block sizes.
In essence, QLoRA takes a nuanced approach to block size selection. The goal is to minimize overhead while retaining needed quantization granularity for accuracy. This is achieved by budgeting memory, quantization profiling, exploiting model structure, and reducing scale value overhead via double quantization. The optimal configuration depends on the model architecture, hardware constraints, and accuracy targets. QLoRA tunes the block sizes accordingly to achieve an efficient balance.
After quantization, LoRA adapters are appended to recover the model’s representational capacity lost by reducing precision. This two-stage approach provides the expressivity of a full-precision model with the nippy size and speed of quantization.
QLoRA further optimizes by quantizing the scale values themselves. For instance, scale could be 32-bit floats quantized to 8 bits. This “double quantization” progressively compresses the model. Together, these enhancements enable fine-tuning giant multibillion parameter models on affordable hardware. By blending techniques, QLoRA pushes efficiency to the edge, placing supercomputer-class AI within a startup’s grasp.
QLoRA Block Size Tuning

The trade-offs with a transformer layer being quantized with different block size configurations
A smaller block size (top path, above) results in more quantized blocks, each with their own scale factor (the alpha values). This enables more precise, fine-grained quantization. However, the large number of scale factors incurs significant memory overhead.
A larger block size (bottom path, above) results in fewer quantized blocks and scale factors. This reduces overhead but at the cost of less precise quantization.
QLoRA tunes the block size to balance this tradeoff, considering factors like:
- Hardware memory constraints
- Sensitivity of layer to quantization error
- Model structure
- Overall accuracy impact
By tuning the block size, QLoRA aims to minimize overhead while retaining the quantization precision needed for a given layer and model architecture.
Pushing the Boundaries of Multimodal Model Efficiency
In a substantial new study1, researchers from Microsoft systematically investigate techniques to maximize efficiency when training massive multimodal models. Their experiments with scaling model size, novel tuning methods and data mixing yield critical insights for economical training without compromising performance.
The Promise and Challenges of Scaling Up
Multimodal models aim to comprehend and reason about images and text together. By pretraining a foundation model on vast datasets then fine-tuning with human-labeled data, researchers have developed multimodal systems like LLaVA that can describe images in detail and solve visual reasoning tasks.
However, state-of-the-art multimodal models often have hundreds of billions of parameters, requiring specialized supercomputing resources to train. As researchers explore scaling to trillions of parameters, efficiency is imperative. This work investigates methods to tune colossal models economically by conducting controlled experiments with the open-source LLaVA framework.

Small vs large multimodal model training hardware requirements
The researchers expand LLaVA from a 13 billion parameter baseline to massive 33 billion and 65-70 billion parameter versions, quantifying their computational footprint. They tune each model variant with full fine-tuning and compare against LoRA, which tunes a small subset of weights. LoRA promises comparable accuracy with reduced training costs, though its benefits for immense multimodal models remain unproven.
Benchmarking Tests and Training Techniques
To rigorously assess performance, the researchers employ diverse benchmarks requiring multimodal reasoning skills. Tests like LLaVA-Bench, MM-VET and MM-Bench evaluate visual interpretation, spatial analysis, detailed text generation and other abilities using novel images and human-crafted questions.
Surprisingly, visually-trained LLaVA also excels at language-only tasks, achieving state-of-the-art on English benchmarks without text-only data. This demonstrates cross-pollination between modalities.
The team tunes models on the LLaVA-80K dataset comprising human-written instructions paired with images. They track GPU hours needed for training as a proxy for cost, noting LoRA’s promise of matching accuracy with significantly fewer resources. Experiments also blend text-only data and increase image resolution to ascertain the impact on model capabilities.
The plot below shows the model performance (accuracy percentage) for different model sizes and training methods. Each bar represents a unique combination of model size and training method (Full, LoRA, or QLoRA).
Note that the LoRA and QLoRA training methods achieve comparable accuracy to full fine-tuning.
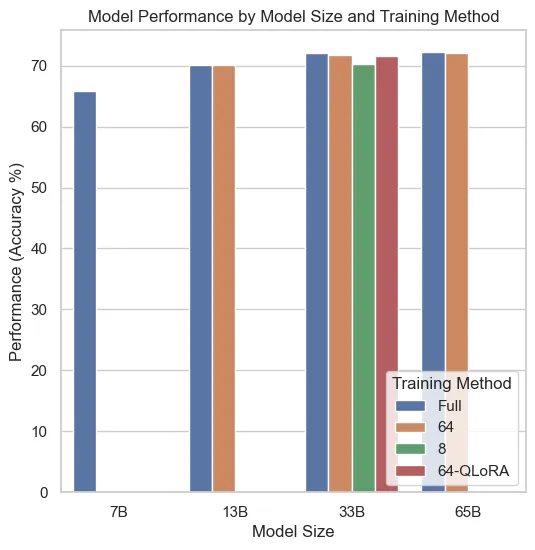
Model performance by size and method
But how do the costs compare? The following plot illustrates the trade-off between performance (accuracy percentage) and compute cost (measured in GPU hours per node). Each point represents a model-training method combination, with different symbols indicating the training method and colors representing the model size.
Note that, for example, the 33B parameter model with a LoRA rank 64 achieves almost the performance of the 66B model, but at half the cost.
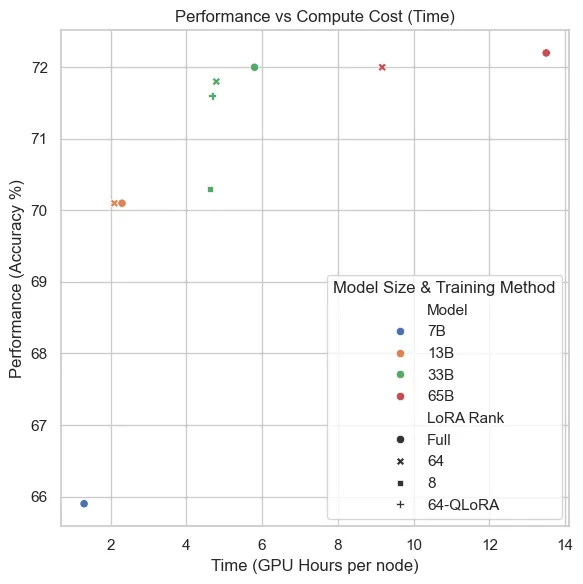
Model performance vs compute cost
Scaling Up: Key Discoveries
The systematic experiments yield pivotal insights about scaling multimodal models both effectively and economically:
- Sheer size matters
- Expanding LLaVA from 13 billion to 65 billion parameters consistently improves multimodal benchmark scores. The giant 65B LLaVA lifts LLaVA-Bench performance over 4 points higher than the 13B version, with especially strong gains on complex reasoning.
- LoRA slashes costs
- For 65B LLaVA, LoRA tuning provides identical benchmark accuracy as full fine-tuning yet requires only 50% of the training time and resources - a major efficiency breakthrough.
- Data diversity delivers
- Mixing text-only and visual data during training provides a 1-2 point gain. Higher resolution 336x336 images compared to 224x224 also boosts performance across model sizes.
- Cross-pollination emerges
- Remarkably, visual training alone enlarges LLaVA’s aptitude for language-only tasks, with the 65B model reaching record scores on English benchmarks.
An Economical Path Forward
By open-sourcing their meticulous scaling experiments and model checkpoints, the researchers enable economical training of capable multimodal AI systems. LoRA tuning proves crucial in making tractable models with unprecedented parameter counts. This study delineates best practices to maximize efficiency without sacrificing accuracy.
The insights distill leading-edge expertise, empowering others to gainfully push boundaries in this burgeoning field even with limited resources. They provide a framework to develop sophisticated models fluent in both images and text within practical constraints. Driven by this pursuit of economical efficiency and multimodal mastery, the researchers aim to make tangible progress on creating flexible, capable AI to assist humanity.
Myriad Use Cases Across Industries
Specialized LLMs tuned with LoRA or QLoRA have an abundance of potential applications:
Healthcare
- Clinical decision support systems providing diagnostic and treatment recommendations based on patient data and medical history. This can aid doctors in making data-driven decisions.
- Intelligent chatbots that allow patients to describe their symptoms and receive triaged advice. They can screen serious conditions and direct patients to seek medical care.
- Medical question answering systems for both professionals and consumers to query symptoms, drug interactions, latest research and more.
- Personalized medicine by tuning models on longitudinal patient profiles and genotypes to predict optimal therapies.
Education
- Intelligent tutoring systems that adapt curriculum pacing and instruction to each student’s strengths and weaknesses.
- Automated content generation for textbooks, problem sets and other teaching materials for more engaging education.
- Curriculum personalization by customizing lessons and assignments to individual learning styles using reinforced prompts.
- Virtual teaching assistants that answer student questions with expert knowledge on demand.
Finance
- Investment advice tuned on financial filings, market data, and news to uncover profitable opportunities or flag risky bets.
- Automated business case analysis to estimate startup costs, predict revenue, identify pitfalls and recommend potential actions.
- Risk assessment for loans and insurance by analyzing applicant details against actuarial data.
- Anomaly detection in transactions and accounting to flag potential fraud earlier.
- Contract review systems that parse legal and financial documents to extract key terms and risks.
Public Sector
- Customer service virtual agents that understand natural queries and provide accurate answers for government services.
- Policy research and analysis aid by scanning legislation, regulations, reports and public reaction.
- Legal assistance tools to empower citizens by explaining laws, identifying forms needed, and guiding case preparation. Internal question answering for government employees to quickly find answers in vast documentation.
Industry
- Predictive maintenance by tuning on equipment sensor data, failure history and operating conditions to optimize repair timing.
- Supply chain optimization tailored on shipment tracking, weather forecasts and inventory flows.
- Enhanced search and retrieval in large enterprise knowledge bases or document repositories.
- Automated data integration between multiple internal systems by learning organization-specific logic.
- Improved product design through generative engineering focused on cost, performance and manufacturability.
- Making Specialized LLMs Economically Viable
Given the LoRA and QloRA implementations, an organization could take a publicly available 10 billion parameter LLM and efficiently tune it on their industry or company specifics for a fraction of full fine-tuning costs. This makes custom LLMs financially viable even for startups and small teams.
Compared to training a model internally, leveraging public LLMs and tuning select weights provides a superior return on investment. The reduced training costs also facilitate continuously updating models as new documents, data sources and use cases arise.
Ongoing Advances to Unlock Future Potential
As LLMs continue aggressively scaling up in size, specialized tuning techniques will only increase in importance for practical adoption. Methods like LoRA and QLoRA will need to evolve along with architectural advances that allow trillions of parameters.
There are several promising directions for continued progress:
- Directly integrating quantization and expert parallelism into models to make tuning inherently efficient.
- Expanding to multilingual tuning by dynamically routing inputs to specialize a single LLM on multiple languages.
- Meta-learning algorithms that optimize the tuning process itself, like automating prompt engineering.
- Reusable tuning across similar tasks by meta-transfer learning.
- Integrating retrieval, knowledge bases and reasoning techniques to reduce the knowledge burden on LLMs.
As tuning techniques become automated, scalable and low-cost, they will unlock specialized LLMs for a sweeping range of applications. Tasks once considered intractable may suddenly become viable. This democratization promises to accelerate real-world beneficial impact, making AI work better for both people and businesses.
Summary
The capabilities of large language models have rapidly advanced, reaching unprecedented scales. However, specialized tuning on diverse tasks remains resource intensive, limiting practical adoption. This is the impetus behind techniques like LoRA and QLoRA that enable efficient tuning.
Their reduced training costs unlock LLMs for a multitude of uses across healthcare, education, finance, industry and more. With efficient tuning, startups and small teams can afford tailored AI and regularly update models. Ongoing advances will further lower barriers, as automated, integrated tuning allows customizing LLMs at the click of a button.
Yet beyond cost savings, the true potential shines through when performing new feats impossible otherwise. By economically harnessing AI’s versatility, problems once intractable become solvable. Students gain personalized education experiences, doctors make data-driven decisions, businesses optimize operations and public services improve. The compounding benefits over time are inestimable.
Ultimately, the measure of success for methods like LoRA and QLoRA will be the previously unimaginable innovations fueled across sectors. The most profound impacts may manifest in applications not yet conceived. By driving efficient tuning, continued progress will bring this potential closer to reality.
References
Footnotes
-
Lu, Y., Li, C., Liu, H., Yang, J., Gao, J. and Shen, Y. (2023). An Empirical Study of Scaling Instruct-Tuned Large Multimodal Models. [online] arXiv.org. doi:https://doi.org/10.48550/arXiv.2309.09958. ↩